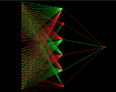
February 16th 2002 - Created random
training tables for a 1 of 32 bits to analog of 0 to 1.
e.g. bit 1 would mean output = (1/32) x 1or bit 22 would
mean output = (22/32) x 1. I fired it up using just 6
neurons and it worked great. It looks really pretty too.
You can see in this image how analog networks are
"naturals" at basic math.
Click to see the finished
picture. http://www.pitstock.com/charts/neural_1of32_to_analog.html |
 |
February 17th 2002 - My first attempt was
to try using an analog network to decode the first two
bytes of a standard 64 bit encrypted letter. It didn't
work very well but it looked really pretty. It was using
somewhere like 100 neurons and it still wasnt happy.
heres a screenshot.
Click to see the finished
picture http://www.pitstock.com/charts/neural_64decode.html |
 |
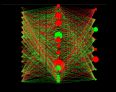
February 17th 2002 - My second attempt at
64 bit decoding. I tried a binary neural network.using 2
byte Input(16bits), 32 hidden nodes, 1 byte output
(8bits). This one solved or "decrypted" the
problem in just a few hours on a pentium 200mhz, except
for 4 characters ....hrmmm I need to modify the training
setup. I have a great fix on paper for this. I will try
and implement it soon and see if my theory is right. This
fix would improve all my neural network goodies.
Click to see the finished
picture http://www.pitstock.com/charts/neural_64decodebinary.html |
 |
February 19th 2002 - My third attempt at
64 bit decoding. After some modifications to the training
sceanario and 8 hours of solid computer crunching the
perfect decoded result was acheived. This used 70 hidden
nodes.
Click to see the finished
picture http://www.pitstock.com/charts/neural_64decide_binary_working.html |
|
| Note: All networks are trained randomly.
I make sure the training data gives no clues by always
presenting training data in random order. |
Previous Page |

